Give every customer their own AI budget
TokenCapAI is the usage, billing, and enforcement layer for anyone building with AI features. Set a budget per customer, department or agent, enforce it in real time, and see exactly what each one consumed — so you bill and manage AI spend accurately.
Reselling AI is easy. Controlling it isn’t.
You can’t see per agent
You charge for AI features but the provider bill is a single lump sum. You’ve no idea what any individual customer actually costs you.
One heavy user sinks the rest
A single customer on a flat plan quietly burns the margin you made on ten others — and you only discover it when the invoice lands.
Your tiers aren’t real limits
Your pricing page promises “500 AI actions a month.” Nothing actually stops a customer using 5,000 and leaving you with the bill.
Three steps to control
No rebuild. Map budgets to the customers you already have and route their AI through us.
Map a budget to each customer
Their plan tier becomes a real limit. Free gets £5, Pro gets £50, Enterprise gets custom — your rules.
Route their AI through TokenCapAI
Point your existing OpenAI or Anthropic SDK at our proxy with one line of config, or report usage via our API.
Enforce and bill on real usage
We block calls the moment a customer hits their limit, and hand you exact per-customer consumption to bill on.
Proxy mode routes calls through us — the simplest path, one-line config. Monitoring mode lets you call the LLM yourself and report events to us — same enforcement, no traffic redirect. Use whichever fits your stack. Choose at any time per agent.
Everything you need to run AI per customer, department or agent
Set up in an afternoon. Works with the providers and SDKs you already use.
Per-customer budgets
Map a budget to every end customer. Their plan becomes a limit that's enforced automatically, in real time.
Real-time enforcement
Block calls the moment a customer hits their limit — within milliseconds, not minutes. Sub-50ms server-side decision.
Per-customer usage datacore
See exactly what each customer consumed. Export it, bill on it, prove it. The number the provider invoice never gives you.
Transparent proxy
Point any OpenAI or Anthropic SDK at our proxy URL. One line of config. Prompts are never stored.
220+ models
OpenAI, Anthropic, Gemini, Mistral, Cohere, DeepSeek. One API, with pricing updated weekly.
Instant alerts
Slack, webhook, or email when a customer hits a cap or crosses 80%. Fires in real time.
Loop protection
Velocity caps catch runaway loops by rate-limiting calls per minute — before a bug burns a customer's whole budget.
Full audit log
Every allowed and blocked call recorded per customer — the source of truth behind what you bill.
Drill into usage
Real product, not a mockup. Daily breakdowns, monthly totals, provider cost per call, CSV export — everything you need to invoice or defend a chargeback.
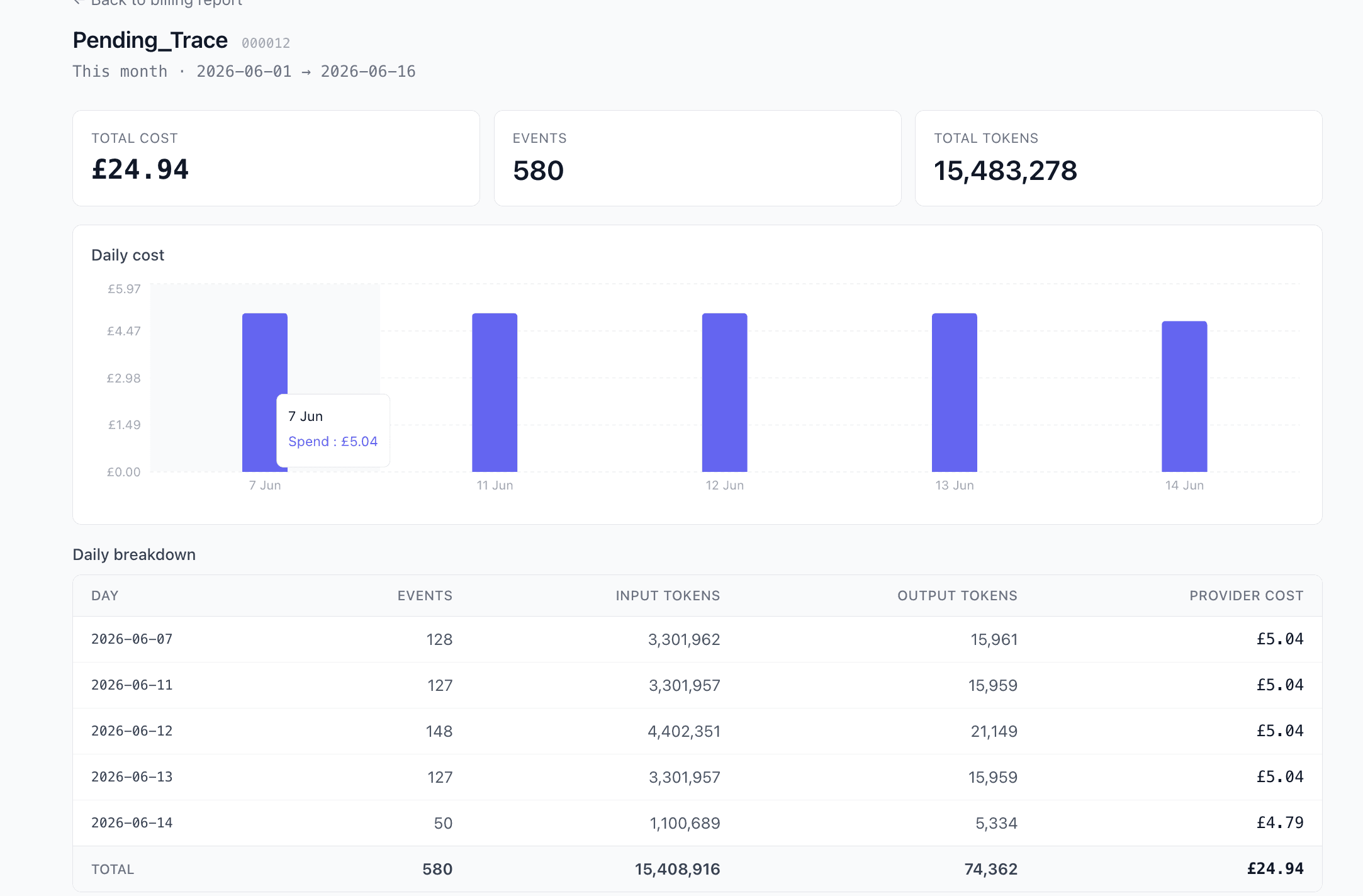
Every row is durably persisted with millisecond timestamps and idempotency keys. The same data you bill on is the data you defend chargebacks with — a single source of truth your finance team can audit on demand.
A complete record
Model, tokens, cost, and decision for every call. Export to CSV or pull via API straight into your billing pipeline.
| Customer | Model | Tokens | Cost | Status |
|---|---|---|---|---|
| Customer A | claude-sonnet-4 | 2,847 | £0.0284 | allowed |
| Customer B | gpt-4o | 4,102 | £0.0512 | allowed |
| Customer D | gpt-4o | 5,891 | £0.0000 | blocked · cap |
| Customer E | gemini-2.5-pro | 12,540 | £0.1891 | allowed |
| Customer C | deepseek-v3 | 15,220 | £0.0198 | allowed |
| Customer A | gpt-4o-mini | 891 | £0.0013 | allowed |
Stop guessing what each customer costs you
Set per-customer AI budgets, enforce them in real time, and bill on exactly what was used.